|
I am a research scientist at Boston Dynamics working on the Atlas humanoid. My research focuses on developing generalist robotic systems capable of long-horizon reasoning, robust manipulation, and natural collaboration with humans. I received my PhD from MIT CSAIL, where I was advised by Leslie Kaelbling, Tomás Lozano-Pérez, and Joshua Tenenbaum. During my PhD, I also co-developed MIT’s 6.S898 Deep Learning course. |

|
|
|


|
Boston Dynamics and TRI Team, including Aidan Curtis Blog Post / Video Large Behavior Models enable Atlas to perform whole-body mobile manipulation. A single language-conditioned diffusion-transformer policy trained on large teleoperation data (real + sim) robustly tackles a wide range of long-horizon, contact-rich tasks. |


|
Aidan Curtis, Hao Tang, Thiago Veloso, Kevin Ellis, Joshua Tenenbaum, Tomas Lozano-Perez, Leslie Pack Kaelbling CoRL, 2025 Paper / Code We aim to address the problem of learning POMDP models from experiences. In particular, we are interested in a subclass of POMDPs wherein the components of the model, including the observation function, reward function, transition function, and initial state distribution function, can be modeled as low-complexity probabilistic graphical models in the form of a short probabilistic program. |

|
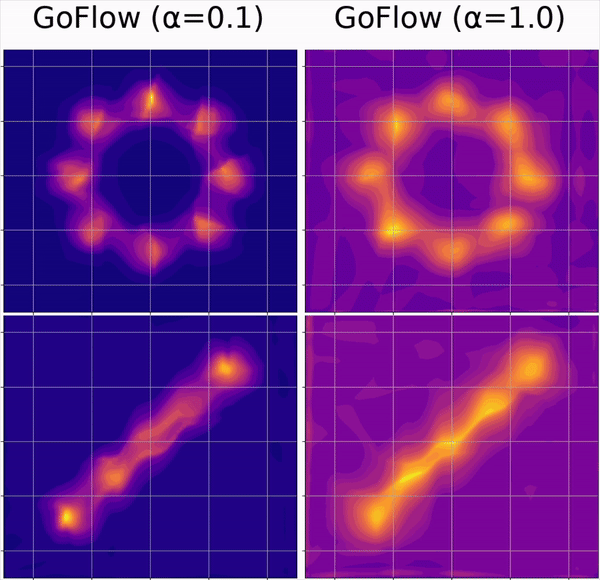
Aidan Curtis, Eric Li, Michael Noseworthy, Nishad Gothoskar, Sachin Chitta, Hui Li, Leslie Pack Kaelbling, Nicole E Carey ICML, 2025 Paper / Code Domain randomization in reinforcement learning is an established technique for increasing the robustness of control policies learned in simulation. In this paper, we present a more flexible representation for domain randomization using normalizing flows, and show how the learned flows can be used as artifacts for multi-step planning. |
|
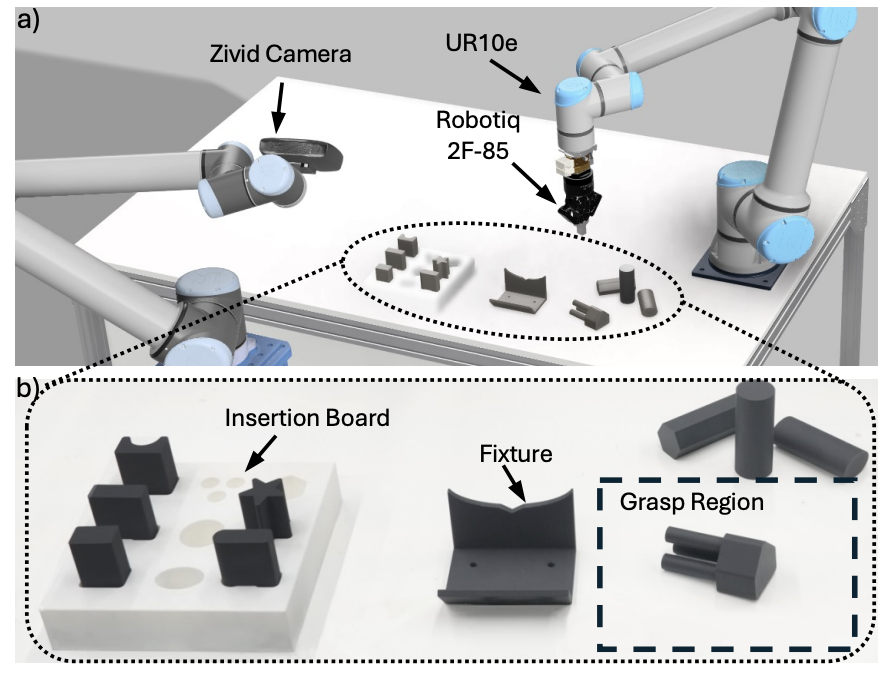
Jiankai Sun, Aidan Curtis, Yang You, Yan Xu, Michael Koehle, Leonidas Guibas, Sachin Chitta, Mac Schwager, Hui Li CoRL, 2025 Website / Paper Generalizable long-horizon robotic assembly requires reasoning at multiple levels of abstraction. We propose a hierarchical modular approach, named ARCH which combines imitation learning and reinforcement learning for long-horizon high-precision assembly in contact-rich settings. |


|
Aidan Curtis*, Nishanth Kumar*, Jing Cao, Tomás Lozano-Pérez, Leslie Pack Kaelbling CoRL, 2024 Website / Paper / Code / Article / Video We prompt the LLM to output code for a function with open parameters, which, together with environmental constraints, can be viewed as a Continuous Constraint Satisfaction Problem (CCSP). This CCSP can be solved through sampling or optimization to find a skill sequence and continuous parameter settings that achieve the goal while avoiding constraint violations. |


|
Aidan Curtis, George Matheos, Nishad Gothoskar, Vikash Mansinghka, Joshua Tenenbaum, Tomás Lozano-Pérez, Leslie Pack Kaelbling RSS, 2024 Website / Paper / Code Integrated task and motion planning (TAMP) has proven to be a valuable approach to generalizable long-horizon robotic manipulation and navigation problems. We propose a strategy for TAMP with Uncertainty and Risk Awareness (TAMPURA) that is capable of efficiently solving long-horizon planning problems with initial-state and action outcome uncertainty, including problems that require information gathering and avoiding undesirable and irreversible outcomes. |


|
Nishad Gothoskar*, Matin Ghavami*, Eric Li* Aidan Curtis, Michael Noseworthy, Karen Chung, Brian Patton William T. Freeman, Joshua B. Tenenbaum, Mirko Klukas, Vikash K. Mansinghka arXiv, 2024 Paper / Code We present Bayes3D, an uncertainty-aware perception system for structured 3D scenes, that reports accurate posterior uncertainty over 3D object shape, pose, and scene composition in the presence of clutter and occlusion. Bayes3D delivers these capabilities via a novel hierarchical Bayesian model for 3D scenes and a GPU-accelerated coarse-to-fine sequential Monte Carlo algorithm. |


|
Aidan Curtis, Leslie Kaelbling, Siddarth Jain ICRA, 2023 Paper In this paper, we propose STRUG, an online POMDP solver capable of handling domains that require long-horizon planning with significant task-relevant and task-irrelevant uncertainty. We demonstrate our solution on several temporally extended versions of toy POMDP problems as well as robotic manipulation of articulated objects using neural perception. |


|
Aidan Curtis*, Jose Muguira-Iturralde*, Yilun Du, Leslie Pack Kaelbling, Tomás Lozano-Pérez ICRA, 2023 Paper / Code In this paper, we examine the problem of visibility aware robot navigation among movable obstacles (VANAMO). A variant of the well-known NAMO robotic planning problem, VANAMO puts additional visibility constraints on robot motion and object movability. |


|
Aidan Curtis*, Xiaolin Fang*, Leslie Pack Kaelbling, Tomás Lozano-Pérez, Caelan Reed Garrett ICRA, 2022 Paper / Video / Code We present a strategy for designing and building very general robot manipulation systems involving the integration of a general-purpose task-and-motion planner with engineered and learned perception modules that estimate properties and affordances of unknown objects. |


|
Aidan Curtis, Tom Silver, Joshua B Tenenbaum, Tomas Lozano-Perez, Leslie Pack Kaelbling AAAI, 2022 Paper / Code Generalized planning accelerates classical planning by finding an algorithm-like policy that solves multiple instances of a task. Here we apply generalized planning to hybrid discrete-continuous task and motion planning. |
|
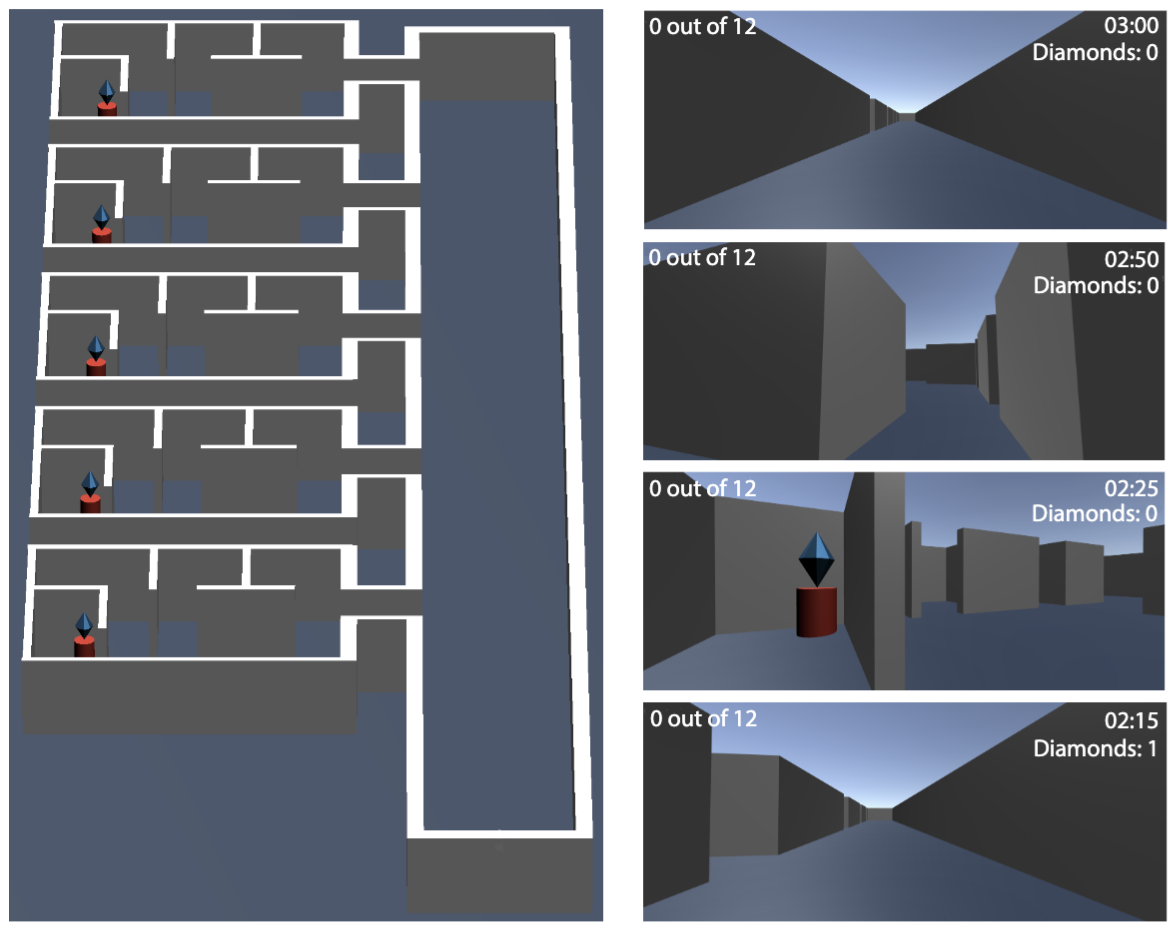
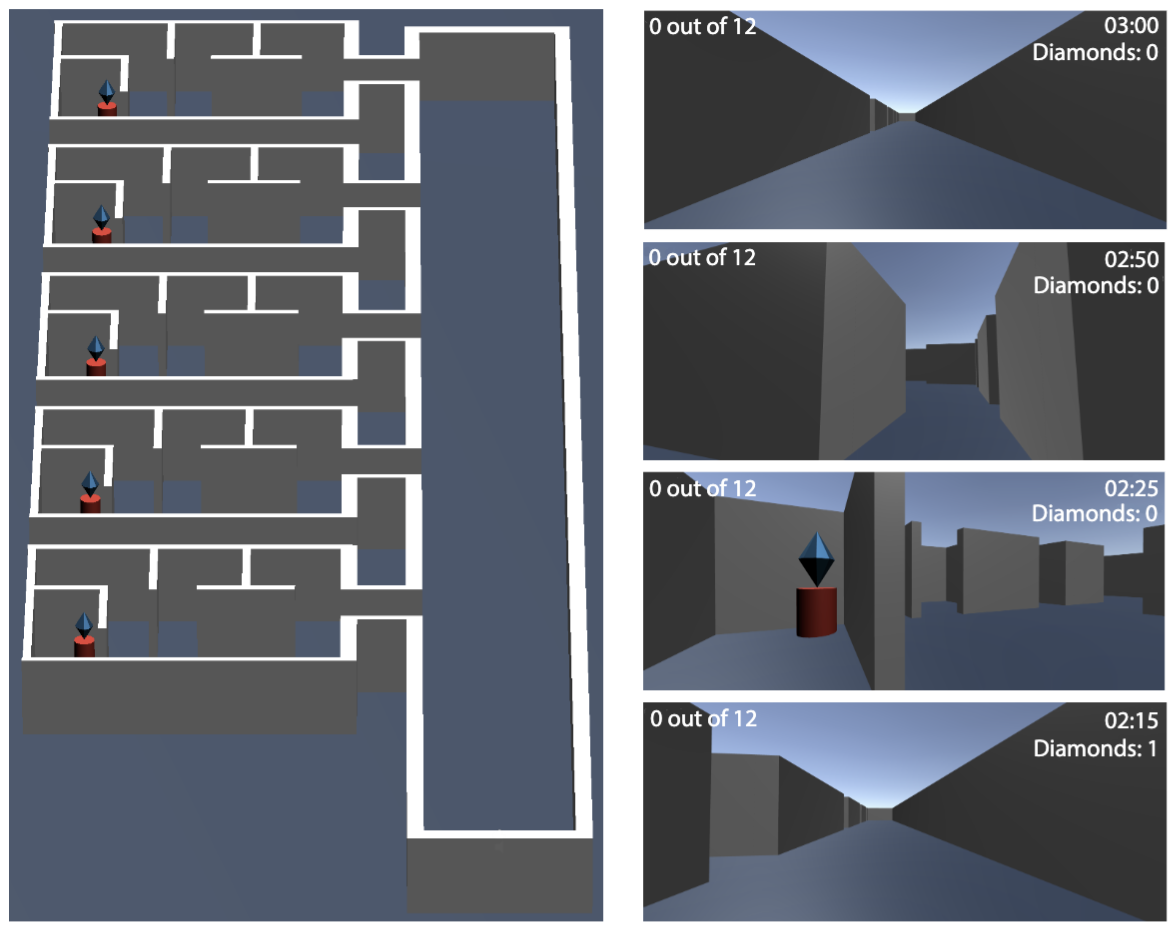
Sugandha Sharma, Aidan Curtis, Marta Kryven, Josh Tenenbaum, Ila Fiete ICLR, 2022 Paper / Code Humans are expert explorers. In this work, we try to understand the computational cognitive mechanisms that support this efficiency can advance the study of the human mind and enable more efficient exploration algorithms. |
 
|
Tom Silver*, Rohan Chitnis*, Aidan Curtis, Joshua Tenenbaum, Tomas Lozano-Perez, Leslie Pack Kaelbling AAAI, 2021 Video / Code / Paper Real-world planning problems often involve hundreds or even thousands of objects, straining the limits of modern planners. In this work, we address this challenge by learning to predict a small set of objects that, taken together, would be sufficient for finding a plan. |
|
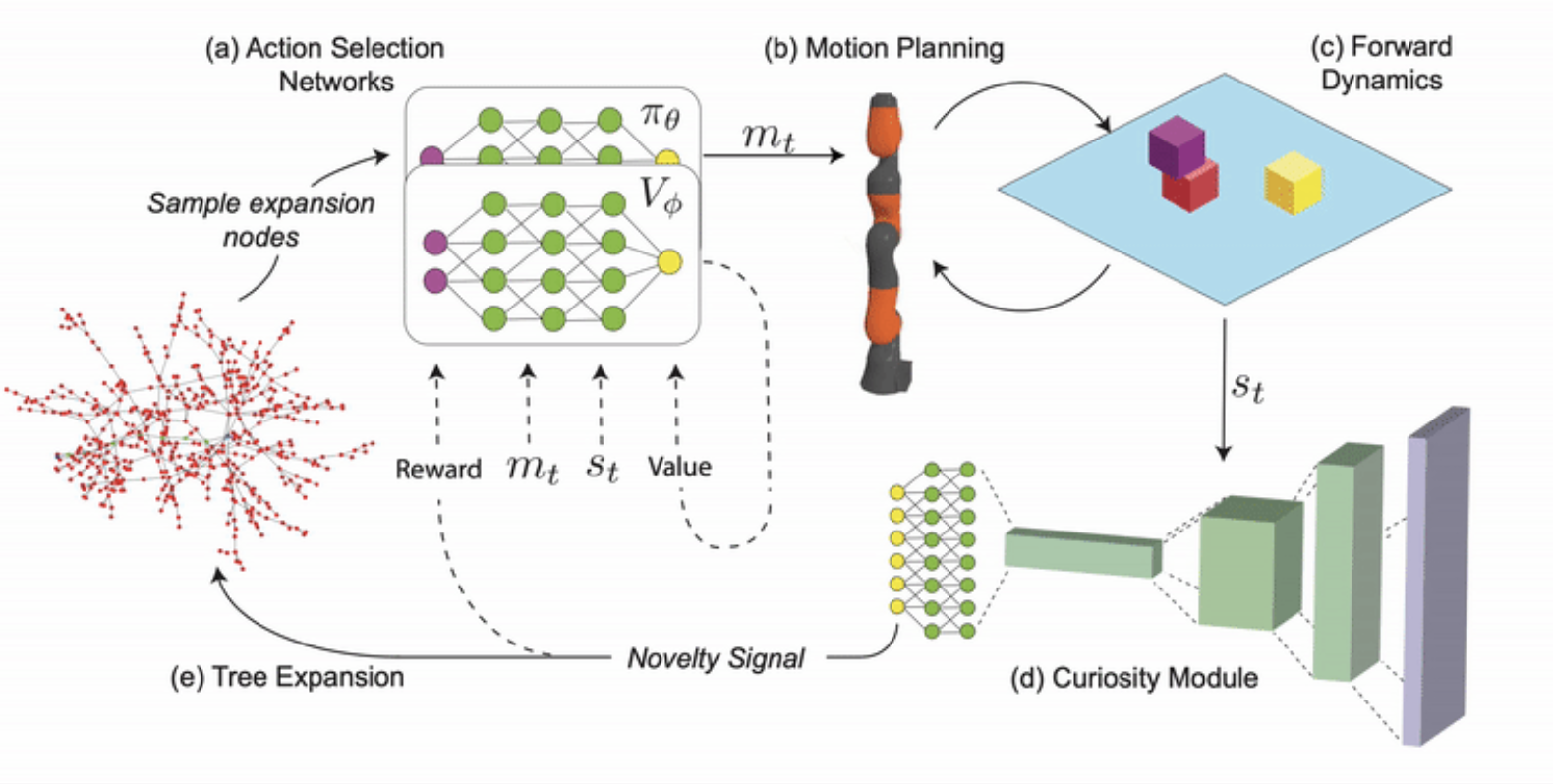
Aidan Curtis, Minjian Xin, Dilip Arumugam, Kevin Feigelis, Daniel Yamins ICML, 2020 Paper / Code / Website A core problem of long-range planning is finding an efficient way to search through the tree of possible action sequences. Here, we propose the Curious Sample Planner (CSP), which fuses elements of TAMP and DRL by combining a curiosity-guided sampling strategy with imitation learning to accelerate planning. |
 
|
Chuang Gan et al., including Aidan Curtis NeurIPS, 2022 Paper / Website / Code We introduce ThreeDWorld (TDW), a platform for interactive multi-modal physical simulation. TDW enables simulation of high-fidelity sensory data and physical interactions between mobile agents and objects in rich 3D environments. |
|
|
|

|
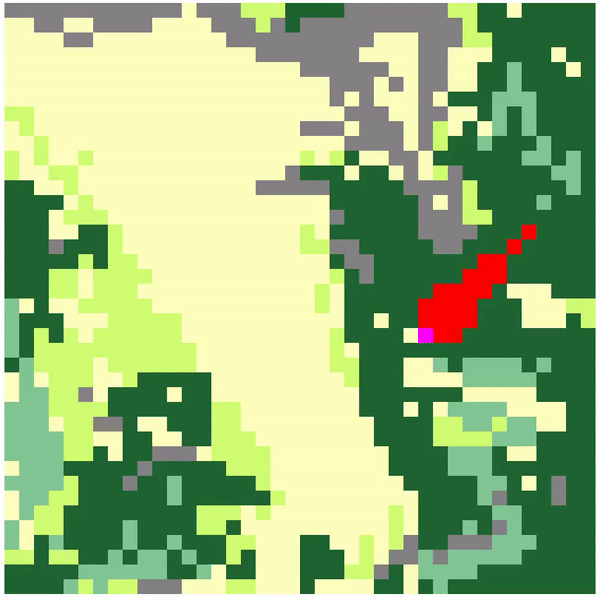
Aidan Curtis*, William Shen* Paper / Project / Code We use Deep Reinforcement Learning to train AI agents which are able to combat wildfires. This page demonstrates the videos of our learned policies. Please see our paper for more details. |


|
Aidan Curtis*, Victor Gonzalez* Paper Predicting short term video dynamics has many useful applications in self-driving cars, weather nowcasting, and model-based reinforcement learning. In this project we provide an in-depth analysis of the available models for video prediction and their strengths and weaknesses in predicting natural sequences of images. |


|
Aidan Curtis, Sophia D’Amico, Andres Gomez, Benjamin Klimko, Zhiyang Zhang Paper / Website / Video / Code In this project we design and build a wireless intracranial neural recording system that uses sparse coding compression to efficiently transmit neural data. |
|
|